Comment doubler une vidéo avec l'IA sans perdre l'énergie de la voix originale
Une analyse technique pour préserver la prosodie vocale, adapter le rythme entre les langues et savoir quand abandonner complètement le doublage.

Vous exportez votre montage final. Vous l'importez dans votre outil de traduction et choisissez le français. La barre de progression atteint les 100 %.
Vous lancez la lecture sur la timeline. L'audio traduit démarre.
Votre pitch enthousiaste pour une nouvelle formation marketing ressemble désormais à l'annonce d'un contrôleur de train fatigué. Les mots sont techniquement corrects. La grammaire est parfaite. Mais l'énergie a totalement disparu.
Nous voyons des agences faire cette erreur chaque semaine. Elles pensent qu'un modèle vocal étiqueté "énergique" s'adaptera naturellement au rythme de leur vidéo source.
Cette supposition ignore le fonctionnement interne de la génération audio. La synthèse vocale classique ne tient absolument pas compte du fichier source.
Les limites techniques de la synthèse vocale classique
La plupart des workflows basiques suivent un chemin destructeur. Le système extrait l'audio et effectue une transcription pour créer un texte brut. Il traduit ce texte dans la langue cible et l'envoie au synthétiseur.
Enfin, il tente d'étirer ou de compresser ce fichier pour correspondre aux marqueurs de temps de la vidéo d'origine.
La suppression de la prosodie vocale
Ce processus linéaire efface toute prosodie. La prosodie désigne la structure rythmique et mélodique de la parole humaine.
Elle englobe les micro-fluctuations de votre voix lorsque vous posez une question. Elle inclut ce léger silence avant de lâcher un hook ou une punchline.
La synthèse standard ignore ces marqueurs physiques. Le moteur ne lit qu'une suite de caractères plats.
Le problème de la densité syllabique
La densité de la langue détruit littéralement le rythme dans ces configurations. Prenez le nombre exact de syllabes.
Le français exige environ 15 à 20 % de mots supplémentaires pour transmettre l'information exacte d'une phrase en anglais. L'espagnol augmente souvent ce volume de 25 %.
Si vous forcez une voix française de synthèse à lire un paragraphe dense dans une fenêtre stricte de cinq secondes, le moteur va accélérer artificiellement la lecture. La voix ressemble alors à celle d'un commissaire-priseur sous pression.
Les respirations naturelles disparaissent. Le registre émotionnel passe de l'expert autoritaire au lecteur paniqué.
À l'inverse, si vous étalez une langue concise sur une longue séquence visuelle, le système allonge les voyelles de manière anormale. La voix traîne. L'énergie retombe. Vous perdez l'attention du spectateur dès les trois premières secondes.
L'anatomie d'une énergie audio préservée
Protéger la performance originale exige un moteur audio capable de lire plus que le texte traduit. Il doit analyser la forme d'onde source elle-même.
Il extrait les propriétés acoustiques du locuteur d'origine et les applique directement sur la piste générée. Nous surveillons quatre marqueurs acoustiques précis pour garantir cette fidélité.
Calquer les variations de fréquence
Le premier est la plage de fréquences. Une voix humaine enthousiaste monte dans les aigus. Une affirmation sérieuse descend dans les graves.
Un processus de doublage correct enregistre ces variations sur la timeline. Il demande ensuite au synthétiseur de reproduire ce contour exact dans la langue cible.
Rythme dynamique et silences
Le deuxième est le débit de parole. Personne ne parle à 140 mots par minute en continu. Nous accélérons sur les mots de liaison.
Nous ralentissons pour insister sur un concept clé. Si votre vidéo originale ralentit sur une phrase spécifique, le doublage traduit doit faire exactement la même chose.
Le troisième est la présence de silences intentionnels. Les pauses portent un poids énorme dans la communication verbale.
Les systèmes standards voient les blancs sur la timeline comme des erreurs à corriger. Si vous marquez une pause de deux secondes pour laisser respirer un argument fort, le moteur de doublage doit recréer cette même respiration.
L'étiquetage des métadonnées émotionnelles
Le quatrième point concerne la catégorie émotionnelle. Les modèles avancés tentent d'attribuer des métadonnées émotionnelles à certaines phrases.
Ils classent un propos comme urgent, empathique, curieux ou autoritaire. Cette approche empêche le système de lire une actualité tragique avec l'enthousiasme d'une publicité.
La règle d'or : choisir entre l'oreille et l'œil
Vous disposez d'outils pour traiter l'audio et d'autres pour afficher du texte visuel. Choisir le bon outil détermine directement votre taux de rétention.
Le doublage n'est pas une solution universelle. Parfois, appliquer une voix synthétique nuit à la performance de votre contenu.
Nous recommandons un protocole strict pour la localisation. Vous devez choisir entre cibler l'oreille ou l'œil du spectateur selon ses habitudes démographiques et le cadrage visuel.
Quand le doublage s'impose
Le doublage gagne à tous les coups lorsque l'audience préfère écouter plutôt que lire. Les données des publicités Facebook montrent que les spectateurs plus âgés dans la région MENA privilégient largement l'audio localisé par rapport au texte.
Ils feront défiler immédiatement une vidéo qui les oblige à lire un texte écrit en petits caractères arabes sur un téléphone. Si vous ciblez un acheteur de 45 ans au Maroc avec une publicité immobilière, vous devez doubler la piste en français ou en darija.
Vous appuyer sur du texte visuel pour cette cible va détruire votre taux de conversion.
Éviter la vallée de l'étrange (uncanny valley)
À l'inverse, vous devez vous limiter aux sous-titres quand le visage du locuteur occupe tout le cadre. Une piste doublée semble profondément déconnectée si la vidéo montre un plan serré où l'on voit clairement les lèvres bouger.
Les mouvements physiques des lèvres ne correspondront jamais aux phonèmes audio. Cela déclenche l'effet de la vallée de l'étrange.
Le spectateur ressent un léger malaise psychologique et passe à la vidéo suivante pour soulager cette friction.
Dans ces scénarios au cadrage serré, abandonnez totalement les outils de doublage. Conservez la piste audio d'origine et son énergie. Laissez le spectateur entendre la voix humaine authentique.
Proposez plutôt la traduction sous forme de texte visuel percutant. Vous pouvez utiliser le sous-titrage mot à mot de CapzAi pour afficher le texte traduit en parfaite synchronisation avec l'audio original.
Appliquer le preset "karaoke" au texte traduit permet à l'œil du spectateur de suivre le mouvement sur l'écran. Cela crée un pont entre l'audio étranger et la compréhension du texte natif.
Vous pouvez en lire davantage sur le choix du bon rythme visuel dans notre guide pour améliorer la rétention grâce à la mise en surbrillance des mots.
Le grand écart linguistique : Anglais, Français, Arabe et Darija
Traduire et doubler entre des familles de langues différentes révèle les failles des outils basiques. Passer de l'anglais au français est un chemin direct.
Ce sont deux langues indo-européennes avec des structures de phrases similaires. Le défi principal reste la longueur brute du texte. Le français augmente considérablement le volume de texte.
Vous réglez ce problème en éditant le script traduit pour le rendre très concis avant de lancer le générateur vocal.
Les inversions structurelles en arabe
Passer de l'anglais à l'arabe introduit une inversion totale de la structure. L'arabe place le verbe avant le sujet dans de nombreux contextes.
Si un anglophone dit "The massive house sits on the hill", une traduction arabe placera l'action avant le sujet. Le poids vocal doit se déplacer entièrement.
Si l'IA calque l'accentuation anglaise sur l'ordre des mots en arabe, elle va accentuer une préposition au lieu d'un nom. Cela détruit la force sémantique de la phrase. Les modèles classiques échouent totalement sur ce point.
CapzAi associe l'accentuation à la véritable signification sémantique. Le moteur ignore le placement brut du mot original sur la timeline.
Le défi du darija
Le darija représente un défi de localisation unique. C'est la langue vernaculaire parlée au Maroc.
Il mélange des influences arabes, françaises, amazighes et espagnoles dans un rythme rapide. La majorité des moteurs IA tentent de traiter le darija avec les règles de prononciation de l'arabe littéral.
Le résultat est incroyablement rigide. Les locuteurs natifs le perçoivent tout de suite comme une voix 100 % synthétique. Nous avons développé un support spécifique pour le darija afin de capter la nature rapide et percussive de ce dialecte.
Si vous ciblez le Maghreb, vous ne pouvez pas vous fier à une synthèse vocale arabe générique. Vous devez choisir le modèle darija dédié pour respecter le rythme culturel.
Auto-clipping : Trouver l'énergie avant de doubler
Vous ne pouvez pas préserver l'énergie si la vidéo source en manque dès le départ. Doubler un webinaire monotone d'une heure donnera une heure traduite toute aussi monotone.
La stratégie de localisation la plus efficace consiste à extraire les moments les plus intenses de la performance humaine avant de lancer la traduction.
Identifier les pics de performance
Notre outil d'auto-clipping analyse les vidéos longues pour repérer les segments avec le plus fort potentiel de rétention. Cet outil ignore totalement les mots-clés génériques.
Il analyse les pics de volume audio, les changements drastiques de rythme, les coupures visuelles soudaines et les expressions faciales concentrées. Quand un créateur se met à parler plus vite et augmente son volume de base, le système identifie un moment de fort intérêt.
Alimenter le modèle acoustique
Vous importez votre vidéo sur la plateforme. Le système vous renvoie une liste de clips verticaux courts.
Vous sélectionnez le passage d'une minute qui contient la livraison vocale la plus dynamique. En isolant cette concentration d'énergie, vous donnez au moteur de doublage IA un gabarit acoustique extrêmement précis à imiter.
La piste étrangère générée sera infiniment plus humaine qu'un dub créé à partir d'un enregistrement plat.
Le guide étape par étape pour une localisation haute fidélité
Créer une vidéo traduite naturelle exige une intervention manuelle volontaire. Vous ne pouvez pas vous contenter d'un traitement automatique en un clic si la qualité vous importe.
Voici le workflow manuel précis pour produire une piste localisée qui sonne purement humaine.
Nettoyer et traduire
Étape 1 : Nettoyer le fichier source. Les modèles audio IA ont énormément de mal avec les interférences de fond.
Si votre vidéo originale contient le bruit de la rue ou une musique forte, le processus d'extraction va échouer. Le système confondra un coup de caisse claire avec une consonne dure. Vous devez isoler une piste vocale propre avant de l'envoyer au moteur de traduction.
Étape 2 : Générer la traduction de base. Importez le fichier vidéo propre et sélectionnez votre langue cible.
CapzAi gère directement la génération en anglais, français, arabe et darija. Le moteur va produire le texte initial et faire un premier rendu de la piste audio.
Auditer les marqueurs de temps
Étape 3 : Auditer les timestamps et la densité du texte. C'est l'étape manuelle la plus critique. Lisez le texte traduit en suivant la timeline visuelle.
Si vous repérez un bloc dense de texte français entassé dans une fenêtre de deux secondes, intervenez immédiatement. Vous pouvez raccourcir le texte traduit en résumant l'idée principale, ou allonger le marqueur de temps visuel si votre logiciel de montage le permet.
Condenser le texte reste souvent la meilleure option. Écrivez strictement pour l'oreille, pas pour un manuel scolaire.
Regénérer et exporter
Étape 4 : Regénérer les passages problématiques. Vous trouverez inévitablement des lignes où la voix générée sonne plate ou comprend mal le contexte régional.
N'acceptez pas ces erreurs. Surlignez la ligne spécifique dans l'éditeur de texte et utilisez la fonctionnalité d'Agent IA pour imposer une autre intonation. Vous pouvez taper "Rends cette phrase plus urgente" ou "Prononce cette marque exactement avec cette orthographe phonétique".
Vous pouvez aussi demander à l'agent d'ajuster l'espacement entre les phrases. Dites à l'agent : "Ajoute une pause d'une seconde avant la dernière phrase".
Cela permet à l'idée précédente de s'installer pleinement dans l'esprit du spectateur. L'agent va regénérer uniquement cette ligne sans modifier le reste de la timeline. Vous pouvez gérer ces modifications chirurgicales directement dans le dashboard de l'agent.
Étape 5 : Lancer l'export final. Une fois que le rythme semble totalement naturel et que le ton correspond à votre énergie d'origine, générez le fichier définitif.
CapzAi fonctionne sur un modèle strict de paiement à l'export, à 20 crédits par minute de vidéo finalisée. Vous ne payez pas les regénérations multiples ni la phase d'essai sur le texte. Vous dépensez vos crédits uniquement sur l'export de votre rendu final.
Cumuler les formats : associer le dub et le texte natif
Beaucoup de créateurs pensent devoir choisir strictement entre le doublage audio et le texte visuel. La stratégie de localisation la plus efficace consiste en fait à superposer les deux formats.
Vous diffusez la piste audio localisée et vous affichez le texte visuel traduit sur l'écran.
La force de la redondance
La redondance fonctionne extrêmement bien. Une grande partie des utilisateurs sur mobile regardent les vidéos en mode silencieux par défaut.
Si vous vous contentez de doubler la piste audio, le spectateur en silencieux n'entend absolument rien et ne voit absolument rien. Si vous ne mettez que des sous-titres, la personne qui écoute en faisant autre chose perd toute l'information.
Associer un dub audio arabe avec des sous-titres arabes mot à mot couvre toutes les habitudes de consommation. Le message marketing central est renforcé deux fois.
Les obstacles typographiques
Cette double approche exige une véritable attention aux détails typographiques. L'arabe et le darija se lisent de droite à gauche (RTL).
Cela engendre des problèmes de rendu massifs sur les outils classiques. Les logiciels de montage vidéo standards détruisent souvent l'écriture RTL. Le logiciel sépare les lettres connectées ou inverse carrément l'ordre de la phrase.
Le texte devient illisible pour un locuteur natif. Vous êtes obligé de passer des heures à retourner manuellement chaque bloc de texte.
CapzAi gère nativement la génération exacte de la disposition RTL. Le texte s'affiche parfaitement. Vous n'avez pas besoin de bricolage manuel ou de plugins de rendu instables. La ponctuation se place du bon côté du bloc de phrase.
Associer les presets visuels à l'audio doublé
Lorsque vous cumulez l'audio doublé et le texte visuel traduit, le design typographique influence fortement la façon dont les spectateurs perçoivent la qualité audio. Un décalage stylistique entre le texte visuel et le ton audio crée une friction cognitive sévère.
CapzAi propose cinq presets de sous-titres. Vous devez les associer stratégiquement à votre format de contenu spécifique.
Choisir le bon preset
Le preset "karaoke" met en évidence les mots individuels exactement au moment où le moteur audio les prononce. Nous recommandons vivement ce preset si vous utilisez un doublage IA pour du contenu technique éducatif.
La mise en surbrillance force le spectateur à suivre de près. Cela crée une expérience visuelle très synchronisée qui masque les petites imperfections de la voix de synthèse.
Le preset "viral pop" utilise des animations de mouvement agressives et des couleurs très vives. Utilisez-le exclusivement pour des tests de produits dynamiques ou des publicités e-commerce au rythme très soutenu.
Ce style visuel renforce directement le rythme énergique. N'utilisez pas ce preset agressif pour des sujets sérieux.
Les presets classiques et personnalisés
Le preset "classic" offre des sous-titres épurés traditionnels en bas de l'écran. C'est le meilleur choix absolu pour la communication d'entreprise (B2B).
Si vous doublez le message d'un cadre dirigeant en français, le texte visuel doit rester totalement discret.
Le preset "docu" propose une mise en page très cinématographique et raffinée. Les réalisateurs de documentaires l'utilisent souvent pour associer ��������������������������������������������������������������������������������������������������������������������isation manuelle poussée. Utilisez-le quand vos guidelines de marque imposent des codes hex, des graisses de police (.ttf) ou des opacités d'ombre spécifiques. Vous pouvez sauvegarder ces paramètres globalement.
Les limites strictes des voix de synthèse
Nous devons être totalement honnêtes sur ce que l'intelligence artificielle ne peut pas faire aujourd'hui. La technologie possède des limites strictes et indéniables.
Si vous tentez de forcer le système au-delà de ces frontières, vous produirez un contenu irregardable.
L'échec face aux rires et à la musique
N'essayez pas de doubler un véritable rire humain. Le rire implique des expirations complexes, imprévisibles, et des vibrations des cordes vocales.
Quand une IA synthétise un rire en pleine phrase, le résultat sonne profondément artificiel et souvent dérangeant. Si votre vidéo source comporte de gros fous rires, gardez la piste audio d'origine intacte et utilisez des sous-titres traduits.
Ne doublez pas de performances musicales. Les modèles vocaux traitent exclusivement les phonèmes parlés. Ils ne comprennent ni la justesse des notes, ni le rythme musical, ni la structure mélodique.
Si un créateur chante brièvement un bout de chanson populaire pour un effet comique, le moteur de doublage lira les paroles exactes sur un ton plat et monotone. Cela détruit complètement la blague prévue.
La barrière du code-switching
Le code-switching détruit complètement les modèles audio. Les personnes bilingues changent fréquemment de langue de façon très rapide au sein d'une même phrase.
Un créateur marocain peut commencer une phrase en darija, insérer une expression française et terminer sa réflexion en darija. Les modèles de langage standards tentent de forcer la phrase française avec les règles phonétiques du darija. Le résultat est un pur charabia audio.
Si votre vidéo repose sur du code-switching rapide, utilisez l'audio d'origine. Appuyez-vous entièrement sur nos workflows de transcription multilingue pour gérer la traduction du texte visuel.
Reconnaître ces limites vous fait gagner des heures de montage frustrantes. Utilisez les outils de doublage exactement là où ils excellent, et écartez-les immédiatement là où ils échouent.
Cas concret : La visite immobilière à Dubaï
Regardons une application pratique de ces règles. Une agence marketing immobilier possède une vidéo en anglais très énergique présentant une propriété de luxe à Dubaï.
L'agent marche rapidement à travers la vaste maison. Il parle vite en montrant des caractéristiques architecturales spécifiques.
L'agence veut lancer une campagne publicitaire agressive ciblant à la fois les investisseurs français et les acheteurs locaux arabophones en simultané.
Clipping et doublage en arabe
D'abord, elle passe la vidéo source dans l'outil d'auto-clipping. La vidéo brute originale dure douze minutes.
L'IA identifie les quatre séquences avec le plus fort potentiel de rétention visuelle : la découverte de la cuisine, la vue depuis le balcon, la salle de bain principale et la piscine privée. Elle les découpe en formats verticaux de 45 secondes.
L'équipe s'attaque d'abord à la version arabe. Comme l'agent immobilier est souvent hors champ pour montrer les pièces, elle décide d'utiliser le doublage vocal IA intégral. Elle génère la piste arabe initiale.
Au premier passage, le texte arabe semble bien trop formel. On dirait un contrat juridique plutôt qu'un argumentaire de vente percutant. Elle surligne la transcription et demande à l'Agent IA : "Réécris cette traduction exacte pour qu'elle soit conversationnelle et enthousiaste."
L'agent met à jour le texte brut et la nouvelle piste audio est générée instantanément. Le rythme correspond maintenant parfaitement à la vitesse de marche de l'agent immobilier. Ils exportent le clip.
Sous-titrer la version française
Ensuite, l'agence prépare la version française. Sur ce clip précis, l'agent se trouve être face caméra en plan très serré.
Elle se souvient de la règle de la vallée de l'étrange et ignore complètement le doublage audio pour cette langue spécifique. Elle conserve l'audio anglais plein d'énergie intact.
Elle génère des sous-titres mot à mot en français. Elle applique le preset "viral pop" pour rendre le texte très visible sur le fond extérieur lumineux, puis exporte le second clip.
L'équipe a réussi à créer deux variations ultra-ciblées d'un même fichier sans enregistrer de nouvel audio physique. Elle a maintenu l'énergie originale dans le dub arabe et évité le malaise visuel dans la version française sous-titrée. Elle a payé exactement 20 crédits par minute.
Faites un test sur votre prochain export en limitant volontairement la longueur du texte. Surlignez un paragraphe traduit très dense dans votre éditeur et supprimez 20 % des adjectifs lourds.
Regénérez cette ligne audio spécifique. Écoutez attentivement la différence dans les espaces de respiration. Vous entendrez immédiatement l'énergie humaine revenir dans la voix.
Articles connexes
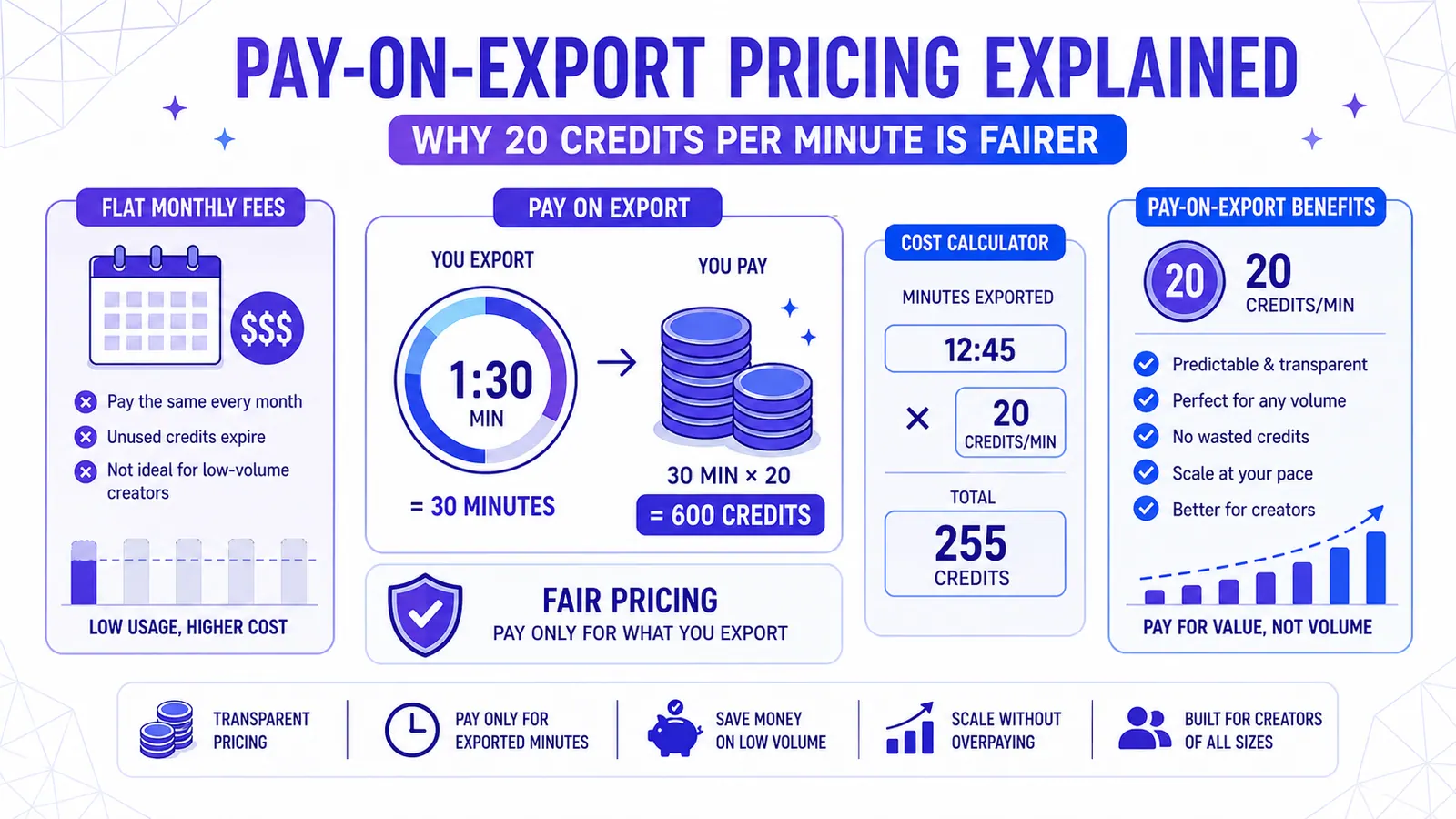
Le prix au paiement à l'exportation expliqué — Pourquoi 20 crédits par minute est plus juste
Les abonnements mensuels fixes pénalisent les créateurs à faible volume et limitent l'expérimentation. CapzAi facture 20 crédits par minute exportée, rendant les outils vidéo IA professionnels abordables et prévisibles.
Lire
Comparatif 2026 des meilleurs traducteurs vidéo IA : CapzAi, HeyGen, Rask
Comparatif 2026 des traducteurs vidéo IA : CapzAi, HeyGen, Rask, Vidnoz, Akool. Précision du lip-sync, support linguistique, et tarification.
Lire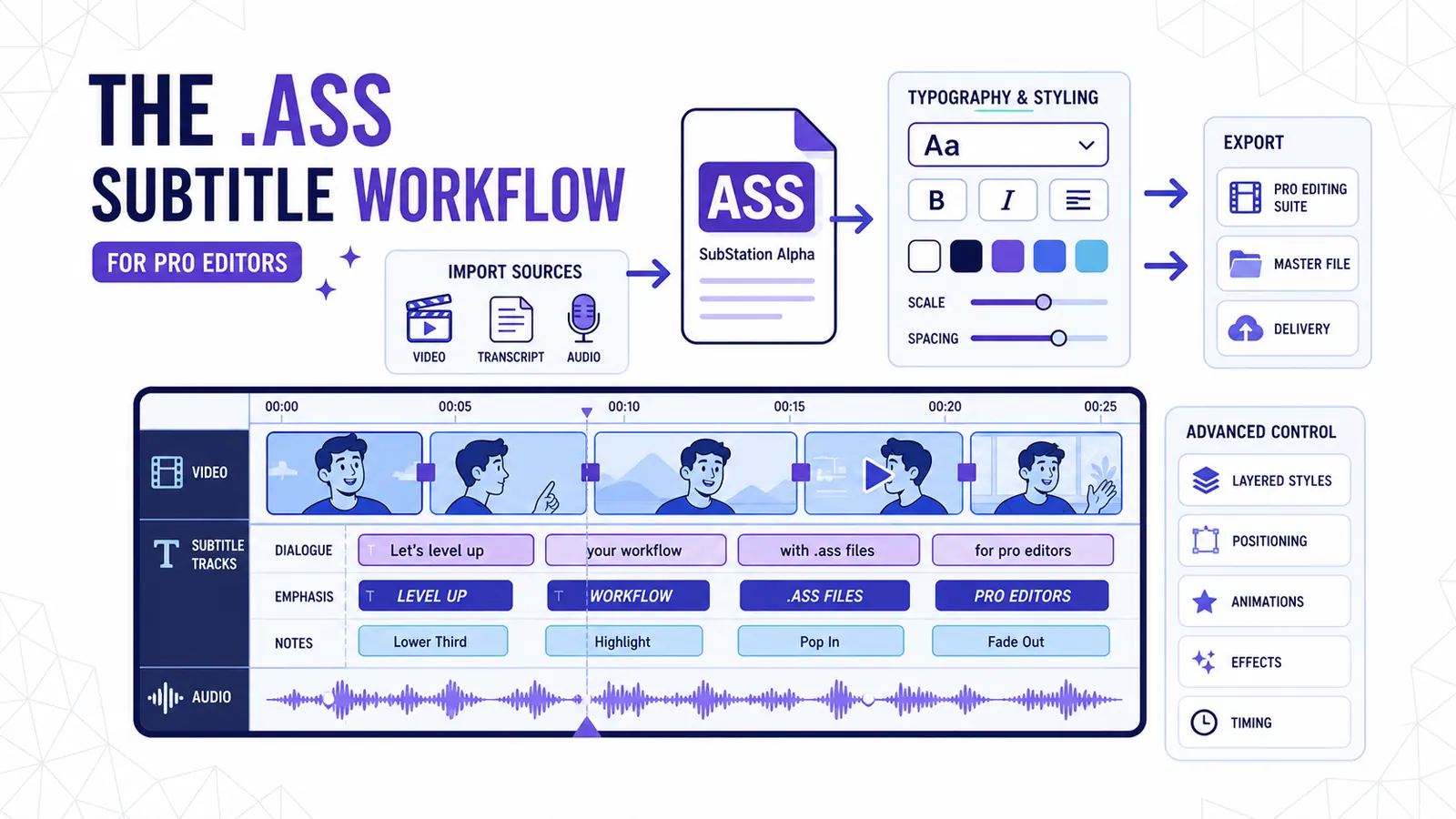
Le workflow de sous-titres .ass pour les monteurs pros
Pourquoi exporter des fichiers Advanced SubStation Alpha est préférable aux fichiers MP4 incrustés ou aux simples SRT pour la post-production professionnelle.
Lire