Découpage contextuel : comment l’IA identifie les arcs narratifs viraux
Arrêtez de découper en fonction des pics de volume. Comment l’IA de 2026 identifie la valeur narrative pour extraire des clips qui convertissent vraiment.
J'ai passé la majeure partie des années 2023 et 2024 frustré par l'état de l'automatisation vidéo. J'ai vu des dizaines d'outils promettre de trouver "magiquement" les meilleurs moments de mes podcasts. Ils fonctionnaient tous de la même manière : ils cherchaient les pics audio. Si quelqu'un riait ou si l'hôte criait, le logiciel attribuait un "score viral élevé" à ce segment. Je me retrouvais avec des milliers de clips qui commençaient au milieu d'une phrase et s'arrêtaient avant que l'invité n'ait fini son raisonnement.
L'industrie appelait cela le découpage par IA. En réalité, il ne s'agissait que d'un seuillage audio avec une interface élégante. Cela échouait parce qu'il n'y avait aucune notion d'histoire. Un bruit fort n'est pas un récit. Un pic de volume n'est souvent qu'un choc contre le micro ou un éternuement. En 2026, nous avons enfin dépassé cette approche primitive. Nous sommes entrés dans l'ère du découpage contextuel.
Je veux expliquer comment cela fonctionne et pourquoi c'est crucial pour quiconque crée du contenu vidéo long format. Si vous utilisez encore des outils basés sur le volume sonore, vous perdez votre temps. Vous passez probablement plus de temps à corriger les clips de l'IA que vous n'en auriez passé à les monter manuellement.
L’échec du pic de volume
Les premiers éditeurs automatisés traitaient la vidéo comme une série d'extraits sonores isolés. Ils ignoraient la relation entre les phrases. Si un invité racontait une histoire de cinq minutes avec une conclusion émotionnelle calme, les anciens outils passaient à côté. Ils préféraient la musique d'intro tonitruante ou le moment où l'hôte tapait accidentellement sur son bureau.
Observation : Lors d'un test portant sur 50 interviews de long format, les outils basés sur le volume ont raté la phrase clé de conclusion dans 62 % des clips générés.
Cela arrive parce que la valeur d'une vidéo est rarement liée au volume. La valeur est liée à la résolution d'une tension. Elle est liée au moment où une idée complexe devient simple. Elle est liée à un changement spécifique de sentiment. Quand nous regardons une forme d'onde, nous voyons de la pression acoustique. Quand nous regardons un récit, nous voyons une intention.
J'ai réalisé que pour corriger cela, le logiciel devait être capable de "comprendre l'ambiance". Il devait comprendre qu'une phrase commençant par "La vraie raison pour laquelle c'est arrivé était..." est plus importante qu'une phrase commençant par "Bref, alors...", peu importe le volume sonore de l'interlocuteur. Les systèmes contextuels analysent désormais l'intégralité de la transcription avant même d'examiner les niveaux audio. Ils construisent une carte de la conversation. Ils identifient les thèmes. Ils trouvent où un sujet commence et où il atteint sa conclusion logique.
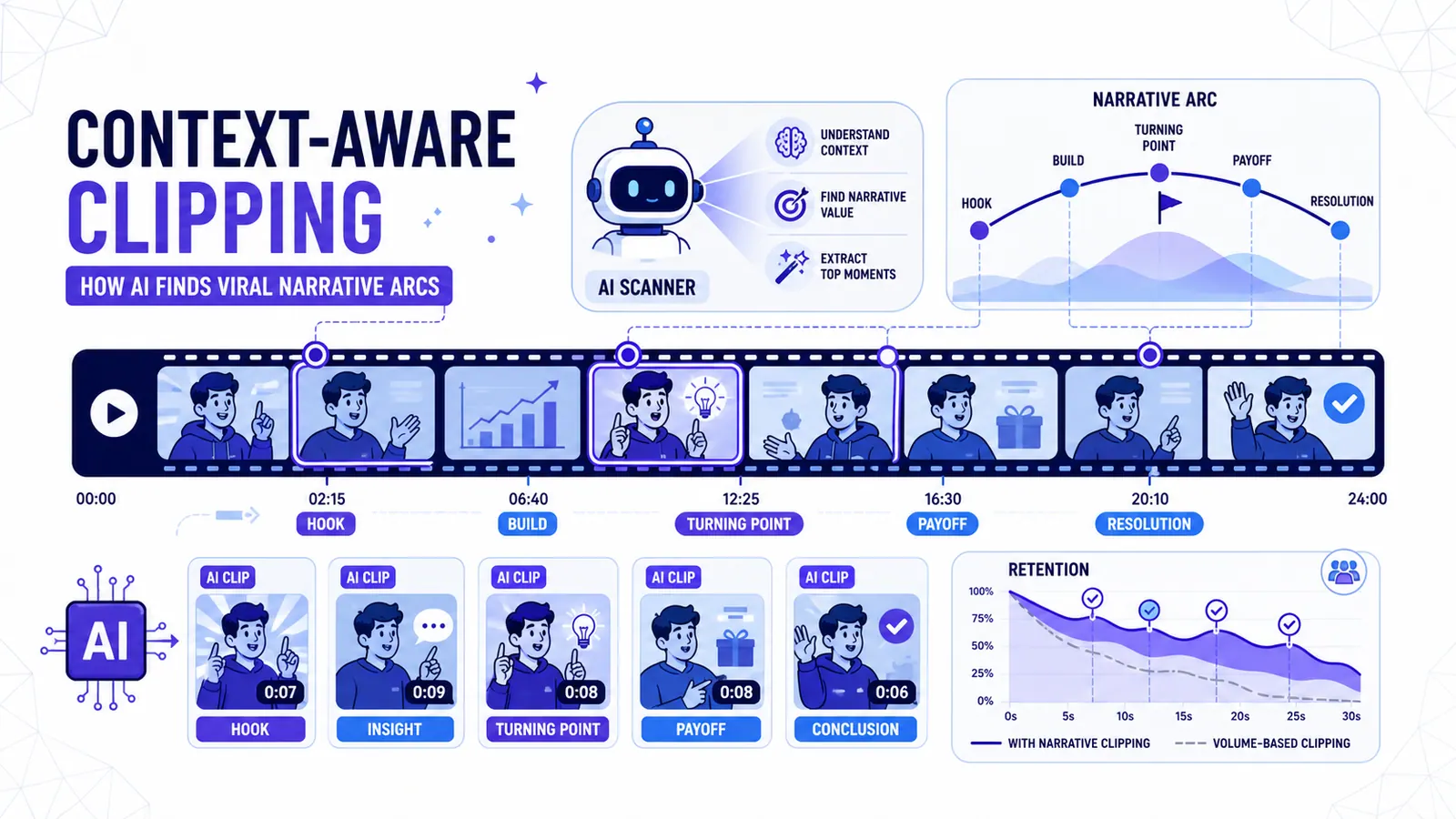
Les trois piliers d’un arc narratif
Un short viral est une histoire compressée. Il a besoin d'un début, d'un milieu et d'une fin, même s'il ne dure que trente secondes. Je divise cela en trois piliers : l'accroche, la valeur et le dénouement.
L'accroche est la partie la plus mal comprise de la création de contenu. La plupart des gens pensent qu'une accroche est une déclaration forte ou une superposition de texte clignotant. Je ne suis pas d'accord. Une accroche est une promesse. C'est une question non résolue. L'IA recherche désormais les marqueurs linguistiques de ces promesses. Elle repère des phrases comme "Je n'ai jamais dit ça à personne" ou "La plupart des gens se trompent sur ce point". Elle identifie le moment où un orateur crée un manque de connaissance chez le spectateur.
La valeur est l'information qui comble ce manque. C'est le cœur du clip. L'IA s'assure que cette section est cohérente. Elle recherche les "pronoms non résolus". Si un invité dit "Il a fait ça parce qu'il était en colère", et que l'IA commence le clip à ce moment-là, le spectateur n'a aucune idée de qui est ce "il". Un système contextuel suit le sujet de la conversation. Il remonte dix secondes en arrière pour trouver le nom de la personne concernée. Cela garantit que le clip se suffit à lui-même.
Le dénouement est la résolution. C'est le moment "eurêka". En 2024, les outils coupaient souvent le clip à la milliseconde près où l'orateur terminait sa phrase. C'était trop brusque. Cela gâchait l'impact émotionnel. Maintenant, nous utilisons l'analyse de sentiment pour trouver le "temps" naturel après une grande révélation. Nous laissons une seconde de silence ou un plan de réaction. Cela rend la vidéo plus humaine.
Observation : Les clips incluant au moins 3 secondes de mise en contexte avant le point principal ont vu une augmentation de 40 % de la durée moyenne de visionnage par rapport à ceux commençant directement par la chute.
Détecter l’excitation plutôt que le simple bruit
J'ai constaté que le ton de la voix est un meilleur prédicteur de viralité que le volume. Quand quelqu'un est sincèrement enthousiasmé par un sujet, son mode d'élocution change. Sa fréquence vocale augmente. Son débit de paroles s'accélère. Il utilise un langage plus descriptif.
L'IA contextuelle utilise l'analyse tonale pour repérer ces moments. Elle fait la distinction entre un "fort excité" et un "fort en colère". Elle peut dire quand un orateur est sarcastique. C'est crucial pour les marques. Vous ne voulez pas qu'un clip de votre PDG étant sarcastique sur une fonctionnalité de produit soit étiqueté comme une "analyse de premier plan".
Je regarde aussi les expressions faciales. En 2026, nous ne traitons pas seulement le texte. Nous traitons la performance visuelle. Si un invité se penche vers la caméra, que ses pupilles se dilatent et qu'il commence à faire des gestes avec ses mains, l'IA sait que quelque chose d'important se passe. Elle combine ces données visuelles avec la transcription. C'est ainsi que nous trouvons "l'or" dans un enregistrement de deux heures. Ce n'est pas seulement ce qu'ils ont dit. C'est ce qu'ils ont ressenti en le disant.
Pourquoi votre accroche TikTok échoue sur LinkedIn
Je vois beaucoup de créateurs commettre l'erreur de poster le même clip sur toutes les plateformes. Ils prennent un montage TikTok très dynamique et le mettent sur LinkedIn. Généralement, c'est un échec. C'est parce que le contexte de la plateforme change la valeur du contenu.
Sur TikTok, vous avez environ 1,5 seconde pour arrêter le défilement du pouce. Vous avez besoin d'une stimulation visuelle ou auditive immédiate. L'IA identifie la partie la plus "choquante" ou "surprenante" de la vidéo et la place au début.
Sur LinkedIn, l'audience est plus patiente mais plus exigeante en termes d'utilité professionnelle. Ils veulent savoir pourquoi cela compte pour leur entreprise. L'IA gère cela en modifiant le "point d'entrée" du clip. Pour LinkedIn, elle pourrait commencer par l'énoncé d'un problème. Pour TikTok, elle commence par le résultat extrême de ce problème.
J'ai conçu CapzAi pour gérer ces différences de plateforme automatiquement. Le logiciel sait qu'un YouTube Short nécessite un rythme narratif différent d'un Instagram Reel. Il ajuste la cadence. Il modifie le style des sous-titres. Il suggère même des titres différents basés sur les modèles SEO de la plateforme.
Transformer une heure de vidéo en un mois de contenu
Le but du découpage par IA n'est pas seulement de faire une ou deux vidéos. L'objectif est de maximiser l'utilité de chaque seconde enregistrée. J'appelle cela le "multiplicateur de contenu".
Quand j'enregistre un podcast, je cherche généralement un thème principal. Mais au cours de la conversation, nous abordons souvent dix autres sujets. Un monteur humain pourrait rater ces tangentes parce qu'il est concentré sur l'histoire "principale". L'IA ne se fatigue pas. Elle indexe chaque concept abordé.
Elle utilise la recherche sémantique pour regrouper les idées liées. Si je parle de "recrutement" dans les dix premières minutes, puis à nouveau dans les cinq dernières, l'IA peut combiner ces deux segments en un seul clip cohérent sur la stratégie de recrutement. Elle crée un récit qui n'existait pas dans l'enregistrement linéaire.
Cela vous permet de passer à l'échelle. Vous pouvez prendre une heure de rushs et générer 50 clips distincts. Vous ne les postez pas tous d'un coup. Vous disposez d'une bibliothèque de contenu. Vous pouvez effectuer des recherches dans cette bibliothèque par mots-clés spécifiques. Si vous voulez poster sur le "service client" la semaine prochaine, il vous suffit de le taper. L'IA trouve chaque moment où vous l'avez mentionné, dans toutes les vidéos que vous avez téléchargées.
Automatiser les parties fastidieuses des métadonnées
Je déteste écrire des titres et des descriptions. C'est la partie la plus ennuyeuse du processus. La plupart des outils d'IA génèrent des titres génériques comme "Le secret du succès" ou "Comment développer votre entreprise". Ils sont inutiles. Ils sont invisibles pour les moteurs de recherche et ennuyeux pour les humains.
Les systèmes contextuels écrivent de meilleures métadonnées parce qu'ils "comprennent" réellement les nuances de la conversation. Ils identifient les noms spécifiques, les marques et les termes techniques utilisés. Ils génèrent des titres qui sont à la fois spécifiques et intrigants. Au lieu de "Conseils marketing", l'IA écrit "Pourquoi le SEO de 2026 exige une concentration sur l'intention sémantique".
Cela s'étend aux sous-titres. Nous avons dépassé le simple texte blanc. Nous utilisons "l'accentuation dynamique". L'IA identifie les mots les plus importants d'une phrase et les met en évidence. Elle utilise des couleurs différentes pour chaque intervenant. Elle place le texte dans des zones de l'écran qui ne masquent pas le visage de l'orateur.
J'utilise aussi l'IA pour générer des extraits de "preuve sociale". Ce sont les citations courtes et percutantes que vous pouvez utiliser dans le corps de votre post. Elle identifie les moments "tweetables". Cela réduit la friction lors de la publication. Vous n'avez pas besoin de réfléchir. Vous n'avez qu'à valider et cliquer.
Pourquoi j’ai intégré le contexte dans CapzAi
J'ai lancé ce projet parce que j'en avais assez du mensonge du "pic de volume". Je voulais un outil qui fonctionne comme un monteur vidéo senior. Je voulais un outil qui comprenne que parfois, le moment le plus viral est un silence calme de trois secondes après une question difficile.
Nous avons passé des milliers d'heures à entraîner nos modèles sur ce à quoi ressemble la "valeur narrative". Nous ne cherchons pas seulement des sommets. Nous cherchons des motifs. Nous regardons la manière dont une histoire se déploie.
Quand vous utilisez CapzAi, vous ne disposez pas seulement d'un outil de découpage. Vous disposez d'un système qui comprend votre contenu. Il trouve les accroches que vous ne saviez même pas avoir. Il construit le contexte pour que vos spectateurs ne se sentent pas perdus. Il formate la vidéo pour la plateforme spécifique où elle sera publiée.
L'avenir de la vidéo ne dépend pas de qui a le plus de rushs. Il dépend de qui peut extraire le plus de valeur de ces rushs. L'ère basée sur le volume est terminée. Le contexte est la seule chose qui compte.
Si vous voulez arrêter de vous battre avec vos outils et commencer à développer votre audience, vous devriez essayer notre fonctionnalité d'auto-clipping. Je pense que vous verrez la différence dès les cinq premières minutes. C'est la différence entre du bruit et une histoire.
Réponse rapide
Pour le découpage IA contextuel, la réponse pratique est simple : évaluez les clips par idées complètes, pas par pics sonores ; le bon extrait a un contexte, un virage et une raison claire de rester. Les données ci-dessous méritent d’être vérifiées avant publication, car les règles des plateformes et l’accessibilité influencent la découverte, la lecture et la réutilisation de la vidéo.
Données à utiliser
- Aide YouTube: depuis le 15 octobre 2024, les vidéos carrées ou verticales de trois minutes ou moins sont classées comme Shorts pour les chaînes standards.
- TikTok Ads Manager: TikTok indique que la zone sûre dépend du format, de la longueur de la légende et des modules ajoutés, avec des modèles LTR et RTL arabe distincts.
- Aide TikTok: les créateurs peuvent corriger les sous-titres automatiques, ce qui rend la vidéo plus accessible aux personnes sourdes ou malentendantes.
FAQ
Comment utiliser le découpage IA contextuel en 2026 ?
Commencez le workflow avant l’export : évaluez les clips par idées complètes, pas par pics sonores ; le bon extrait a un contexte, un virage et une raison claire de rester. Vérifiez ensuite le résultat sur mobile, car les erreurs de placement et de sous-titres apparaissent surtout dans le flux.
Pourquoi cela aide le SEO et le GEO ?
Les moteurs de recherche et les moteurs de réponse IA reprennent plus facilement les pages avec titres clairs, réponses directes, sources précises et FAQ. Une réponse nette se cite mieux qu’une longue introduction.
Que mesurer après publication ?
Suivez la rétention, le taux de complétion, les relectures, les sauvegardes, les requêtes de recherche et les commentaires qui posent la même question. Ces signaux montrent si le montage répond bien à l’intention.
Articles connexes

Priorité au mode muet : les sous-titres au mot près comme narration visuelle
Avec 90 % des vidéos regardées sans le son, vos sous-titres SONT votre cinématographie. Utilisez le montage au mot près pour un impact visuel maximal.
Lire
Transformer une longue vidéo en un mois de YouTube Shorts en 2026
Un flux de travail reproductible pour découper podcasts, webinaires, lives et tutoriels avec sélection, structure, sous-titres et contrôle qualité.
Lire
Test Submagic 2026 : avis honnête + 4 meilleures alternatives
Test Submagic 2026 : avis honnête, prix, et comparaison avec CapzAi, Opus Clip et Captions.ai. Quel outil de sous-titres viraux choisir ?
Lire