القص المدفوع بالسياق: كيف يعثر الذكاء الاصطناعي على المسارات السردية الرائجة
توقف عن القص بناءً على طفرات الصوت. كيف يحدد الذكاء الاصطناعي في عام 2026 القيمة السردية لاستخراج مقاطع تحقق تحويلاً حقيقياً.
لقد قضيت معظم عامي 2023 و2024 في حالة من الإحباط تجاه وضع أتمتة الفيديو. شاهدت عشرات الأدوات التي تعد بالعثور "سحرياً" على أفضل الأجزاء في البودكاست الخاص بي. كانت جميعها تعمل بنفس الطريقة؛ تبحث عن ذروات الصوت. إذا ضحك شخص ما أو صرخ المضيف، يضع البرنامج "درجة انتشار عالية" على ذلك الجزء. وانتهى بي الأمر بآلاف المقاطع التي تبدأ في منتصف جملة وتنتهي قبل أن ينهي الضيف فكرته.
أطلقت الصناعة على هذا اسم "القص بالذكاء الاصطناعي"، لكنه في الحقيقة لم يكن سوى تحديد عتبات الصوت بواجهة براقة. لقد فشل لأنه لم يمتلك أي مفهوم عن القصة. فالضوضاء الصاخبة ليست سرداً، وطفرة الصوت غالباً ما تكون مجرد اصطدام بالميكروفون أو عطسة. في عام 2026، تجاوزنا أخيراً هذا النهج البدائي، ودخلنا عصر القص المدرك للسياق.
أريد أن أشرح كيف يعمل هذا ولماذا يهم أي شخص يصنع فيديوهات طويلة. إذا كنت لا تزال تستخدم أدوات تعتمد على مستوى الصوت، فأنت تضيع وقتك. من المحتمل أنك تقضي وقتاً في إصلاح مقاطع "الذكاء الاصطناعي" أكثر مما كنت ستقضيه في تحريرها يدوياً.
فشل طفرات الصوت
عاملت أدوات التحرير المؤتمتة المبكرة الفيديو وكأنه سلسلة من المقتطفات الصوتية، متجاهلة العلاقة بين الجمل. إذا روى ضيف قصة مدتها خمس دقائق بنهاية عاطفية هادئة، كانت الأدوات القديمة تفوتها، وتفضل بدلاً منها موسيقى المقدمة الصاخبة أو الجزء الذي ضرب فيه المضيف مكتبه بالخطأ.
ملاحظة: في اختبار شمل 50 مقابلة طويلة، فات الأدوات المعتمدة على حجم الصوت جملة "النهاية الحاسمة" في 62% من المقاطع التي أنتجتها.
يحدث هذا لأن القيمة في الفيديو نادراً ما ترتبط بحجم الصوت، بل ترتبط بحل التوتر، وباللحظة التي تصبح فيها الفكرة المعقدة بسيطة، وبتغير محدد في المشاعر. عندما ننظر إلى شكل الموجة، نرى ضغط الهواء، لكن عندما ننظر إلى السرد، نرى القصد.
أدركت أنه لإصلاح ذلك، يحتاج البرنامج إلى "قراءة الغرفة". كان بحاجة لفهم أن جملة تبدأ بـ "السبب الحقيقي وراء حدوث ذلك هو..." هي أهم من جملة تبدأ بـ "على أي حال، لذا..." بغض النظر عن مدى ارتفاع صوت المتحدث. تقوم الأنظمة المدركة للسياق الآن بتحليل النص الكامل قبل حتى النظر في مستويات الصوت؛ حيث تبني خريطة للمحادثة، وتحدد المواضيع، وتعرف أين يبدأ الموضوع وأين يصل إلى استنتاجه المنطقي.
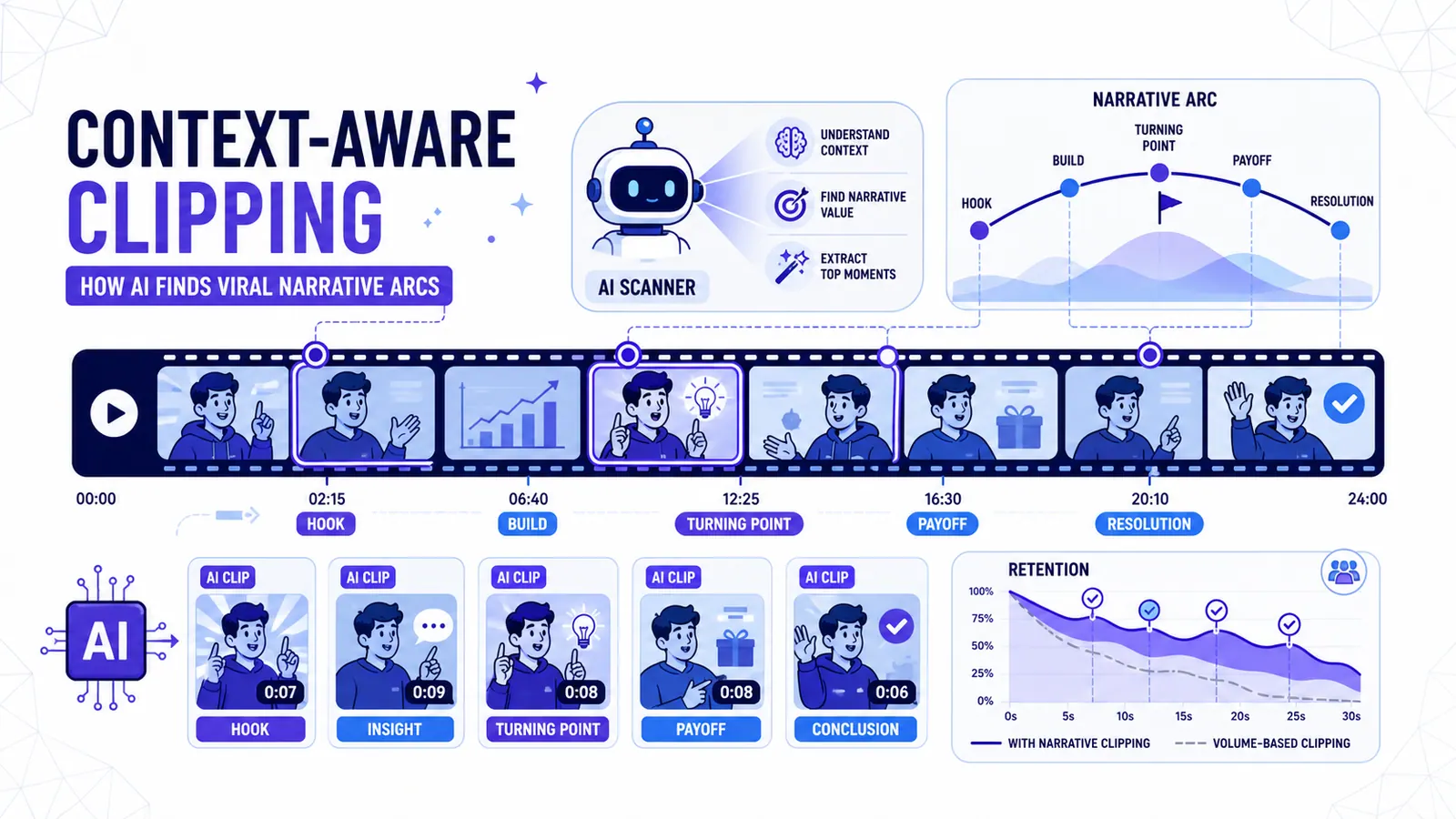
الركائز الثلاث للمسار السردي
المقطع القصير الناجح (Viral Short) هو قصة مضغوطة. يحتاج إلى بداية ووسط ونهاية، حتى لو استغرق ثلاثين ثانية فقط. أقسم هذا إلى ثلاث ركائز: الخطاف (The hook)، والقيمة (The value)، والنتيجة (The payoff).
الخطاف هو الجزء الأكثر سوءاً في الفهم في صناعة المحتوى. يعتقد معظم الناس أن الخطاف هو تصريح صاخب أو نص وامض، لكني أختلف مع ذلك. الخطاف هو وعد، هو سؤال لم تتم الإجابة عليه. يبحث الذكاء الاصطناعي الآن عن العلامات اللغوية لهذه الوعود، مثل عبارات "لم أخبر أحداً بهذا من قبل" أو "معظم الناس يخطئون في هذا". إنه يحدد اللحظة التي يخلق فيها المتحدث فجوة في معرفة المشاهد.
القيمة هي المعلومات التي تملأ تلك الفجوة، وهي صلب المقطع. يضمن الذكاء الاصطناعي أن يكون هذا القسم متسقاً، حيث يبحث عن "الضمائر غير المحلولة". إذا قال الضيف "لقد فعل ذلك لأنه كان غاضباً"، وبدأ الذكاء الاصطناعي المقطع هناك، فلن يكون لدى المشاهد أدنى فكرة عمن هو "هو". يتتبع النظام المدرك للسياق موضوع المحادثة، ويعود عشر ثوانٍ للخلف للعثور على اسم الشخص الذي تتم مناقشته، مما يضمن أن المقطع قائم بذاته ومفهوم.
النتيجة هي الحل، هي لحظة "آها". في عام 2024، كانت الأدوات غالباً ما تقص المقطع في اللحظة التي ينهي فيها المتحدث جملته، مما يجعله يبدو مفاجئاً ويدمر التأثير العاطفي. الآن، نستخدم تحليل المشاعر للعثور على "الإيقاع" الطبيعي بعد الكشف الكبير، ونترك ثانية من الصمت أو لقطة رد فعل، مما يجعل الفيديو يبدو إنسانياً.
ملاحظة: المقاطع التي تضمنت 3 ثوانٍ على الأقل من التمهيد قبل النقطة الرئيسية شهدت زيادة بنسبة 40% في متوسط مدة المشاهدة مقارنة بتلك التي بدأت مباشرة عند ذروة الحديث.
اكتشاف الحماس بدلاً من الضوضاء فقط
لقد وجدت أن نبرة الصوت هي مؤشر أفضل للانتشار من حجم الصوت. عندما يكون شخص ما متحمساً حقاً لموضوع ما، تتغير أنماط كلامه؛ ترتفع حدة صوته، وتزداد كلماته في الدقيقة، ويستخدم لغة وصفية أكثر.
يستخدم الذكاء الاصطناعي المدرك للسياق التحليل النبرات الصوتية للعثور على هذه اللحظات. إنه يميز بين "الصخب المتحمس" و"الصخب الغاضب". يمكنه معرفة متى يكون المتحدث ساخراً، وهذا أمر حيوي للعلامات التجارية؛ فأنت لا تريد تسمية مقطع لمديرك التنفيذي وهو يسخر من ميزة منتج كـ "رؤية ثاقبة".
أقوم أيضاً بالنظر في تعبيرات الوجه. في عام 2026، لا نعالج النصوص فقط، بل نعالج الأداء البصري. إذا مال الضيف نحو الكاميرا، واتسعت حدقتا عينيه، وبدأ بالإيماء بيديه، يعرف الذكاء الاصطناعي أن شيئاً مهماً يحدث. يدمج هذه البيانات البصرية مع النص، وهكذا نجد "الذهب" في تسجيل مدته ساعتان. الأمر لا يتعلق فقط بما قالوه، بل بما شعروا به عندما قالوه.
لماذا يفشل خطاف TikTok الخاص بك على LinkedIn
أرى العديد من المبدعين يرتكبون خطأ نشر نفس المقطع على كل منصة. يأخذون مونتاجاً عالي الطاقة من TikTok ويضعونه على LinkedIn، وعادة ما يفشل. هذا لأن سياق المنصة يغير قيمة المحتوى.
على TikTok، لديك حوالي 1.5 ثانية لإيقاف إصبع المستخدم عن التمرير. أنت بحاجة إلى تحفيز بصري أو سمعي فوري. يحدد الذكاء الاصطناعي الجزء الأكثر "صدمة" أو "مفاجأة" في الفيديو ويضعه في البداية.
على LinkedIn، الجمهور أكثر صبراً ولكنه أكثر تطلباً للمنفعة المهنية. يريدون معرفة سبب أهمية هذا لأعمالهم. يتعامل الذكاء الاصطناعي مع هذا عن طريق تغيير "نقطة الدخول" للمقطع. بالنسبة لـ LinkedIn، قد يبدأ بتوضيح مشكلة ما، أما بالنسبة لـ TikTok، فيبدأ بالنتيجة القصوى لتلك المشكلة.
لقد بنيت CapzAi للتعامل مع هذه الاختلافات بين المنصات تلقائياً. يعرف البرنامج أن YouTube Shorts يحتاج إلى إيقاع سردي مختلف عن Instagram Reels، فيقوم بتعديل السرعة، وتغيير أنماط العناوين الفرعية، بل ويقترح عناوين مختلفة بناءً على أنماط تحسين محركات البحث (SEO) الخاصة بكل منصة.
تحويل ساعة من الفيديو إلى محتوى يكفي لشهر
هدف القص بالذكاء الاصطناعي ليس فقط صنع فيديو أو اثنين، بل تعظيم الاستفادة من كل ثانية تسجلها. أسمي هذا "مضاعف المحتوى".
عندما أسجل بودكاست، عادة ما أبحث عن موضوع رئيسي واحد، لكن خلال المحادثة، غالباً ما نتطرق إلى عشرة مواضيع أخرى. قد يفوت المحرر البشري هذه التفريعات لأنه يركز على القصة "الرئيسية". أما الذكاء الاصطناعي فلا يتعب؛ إنه يفهرس كل مفهوم تمت مناقشته.
يستخدم البحث الدلالي لتجميع الأفكار ذات الصلة. إذا تحدثت عن "التوظيف" في الدقائق العشر الأولى ثم مرة أخرى في الدقائق الخمس الأخيرة، يمكن للذكاء الاصطناعي دمج هذين الجزأين في مقطع واحد متماسك حول استراتيجية التوظيف. إنه يخلق سرداً لم يكن موجوداً في التسجيل الخطي الأصلي.
هذا يتيح لك التوسع؛ يمكنك أخذ ساعة واحدة من اللقطات وتوليد 50 مقطعاً متميزاً. لا تنشرها كلها دفعة واحدة، بل يصبح لديك مكتبة من المحتوى يمكنك البحث فيها عن كلمات مفتاحية محددة. إذا أردت النشر عن "خدمة العملاء" الأسبوع المقبل، فما عليك سوى كتابة ذلك، وسيعثر الذكاء الاصطناعي على كل لحظة ذكرتها فيها، عبر كل فيديو قمت بتحميله على الإطلاق.
أتمتة الأجزاء المملة من البيانات الوصفية
أنا أكره كتابة العناوين والأوصاف، فهي الجزء الأكثر رتابة في العملية. تولد معظم أدوات الذكاء الاصطناعي عناوين عامة مثل "سر النجاح" أو "كيف تنمي عملك"، وهي عناوين عديمة الفائدة؛ فهي غير مرئية لمحركات البحث ومملة للبشر.
تكتب الأنظمة المدركة للسياق بيانات وصفية أفضل لأنها "تفهم" حقاً تفاصيل المحادثة. تحدد الأسماء والعلامات التجارية والمصطلحات التقنية المستخدمة، وتولد عناوين محددة ومثيرة للفضول. بدلاً من "نصائح تسويقية"، يكتب الذكاء الاصطناعي "لماذا يتطلب SEO في 2026 التركيز على القصد الدلالي".
يمتد هذا ليشمل العناوين الفرعية (Captions). لقد تجاوزنا النص الأبيض البسيط؛ نحن نستخدم "التأكيد الديناميكي". يحدد الذكاء الاصطناعي الكلمات الأكثر أهمية في الجملة ويسلط الضوء عليها، ويستخدم ألواناً مختلفة لمختلف المتحدثين، ويضع النص في مناطق من الشاشة لا تغطي وجه المتحدث.
أستخدم الذكاء الاصطناعي أيضاً لتوليد مقتطفات "الدليل الاجتماعي" (Social proof). هذه هي الاقتباسات القصيرة والقوية التي يمكنك استخدامها في نص منشورك. إنه يحدد اللحظات "القابلة للتغريد"، مما يقلل من عناء النشر. لست مضطراً للتفكير؛ فقط راجع واضغط.
لماذا وضعت السياق في CapzAi
بدأت هذا المشروع لأني سئمت من كذبة "طفرة الصوت". أردت أداة تعمل كمحرر فيديو خبير؛ أداة تفهم أن اللحظة الأكثر انتشاراً أحياناً هي صمت هادئ لمدة ثلاث ثوانٍ بعد سؤال صعب.
لقد قضينا آلاف الساعات في تدريب نماذجنا على شكل "القيمة السردية". نحن لا نبحث فقط عن القمم، بل نبحث عن الأنماط، وعن الطريقة التي تتكشف بها القصة.
عندما تستخدم CapzAi، فأنت لا تحصل فقط على أداة قص، بل تحصل على نظام يفهم محتواك. يعثر على الخطافات التي لم تكن تعلم بوجودها، ويبني السياق حتى لا يشعر مشاهدوك بالضياع، وينسق الفيديو للمنصة المحددة التي سيعرض عليها.
مستقبل الفيديو لا يتعلق بمن يملك أكبر قدر من اللقطات، بل بمن يمكنه استخراج أكبر قدر من القيمة منها. لقد انتهى عصر الاعتماد على حجم الصوت، والسياق هو الشيء الوحيد الذي يهم الآن.
إذا كنت تريد التوقف عن محاربة أدواتك والبدء في تنمية جمهورك، فعليك تجربة ميزة القص التلقائي لدينا. أعتقد أنك سترى الفرق في الدقائق الخمس الأولى؛ إنه الفرق بين الضجيج والقصة.
إجابة سريعة
بالنسبة إلى القص السياقي بالذكاء الاصطناعي، الإجابة العملية هي: قيّم المقاطع بناءً على اكتمال الفكرة لا ارتفاع الصوت؛ المقطع الجيد له تمهيد وتحول وسبب واضح لمواصلة المشاهدة. النقاط أدناه تستحق المراجعة قبل النشر، لأن قواعد المنصات ومعايير الإتاحة تحدد هل يمكن للجمهور العثور على الفيديو وقراءته وإعادة استخدامه.
نقاط مدعومة بالبيانات
- مساعدة YouTube: منذ 15 أكتوبر 2024، تُصنّف الفيديوهات العمودية أو المربعة التي لا تتجاوز ثلاث دقائق كـ Shorts في القنوات القياسية.
- TikTok Ads Manager: توضح TikTok أن المنطقة الآمنة تتغير حسب نسبة العرض وطول الوصف والإضافات، مع ملفات منفصلة للاتجاه LTR والعربية RTL.
- مساعدة TikTok: يمكن لصناع المحتوى تعديل التسميات التلقائية، وهذا يساعد المشاهدين الصم أو ضعاف السمع على فهم الفيديو.
الأسئلة الشائعة
كيف أستخدم القص السياقي بالذكاء الاصطناعي في 2026؟
ابدأ سير العمل قبل التصدير: قيّم المقاطع بناءً على اكتمال الفكرة لا ارتفاع الصوت؛ المقطع الجيد له تمهيد وتحول وسبب واضح لمواصلة المشاهدة. ثم راجع النتيجة على الهاتف، لأن أخطاء التخطيط والتسميات تظهر غالباً داخل الخلاصة لا داخل المحرر.
لماذا يساعد هذا في SEO وGEO؟
محركات البحث ومحركات الإجابة بالذكاء الاصطناعي تلتقط الصفحات التي تحتوي على عناوين واضحة وإجابات مباشرة وادعاءات موثقة وأسئلة شائعة. الإجابة الصريحة أسهل في الاقتباس من مقدمة طويلة.
ما الذي يجب قياسه بعد النشر؟
راقب الاحتفاظ، ونسبة الإكمال، وإعادة المشاهدة، والحفظ، وعبارات البحث، والتعليقات التي تكرر السؤال نفسه. هذه الإشارات توضح هل كان المونتاج مناسباً لنية المشاهد أم لا.
مقالات ذات صلة

أولوية كتم الصوت: الشرح النصي على مستوى الكلمة كسرد بصري
مع مشاهدة 90% من الفيديوهات بدون صوت، فإن شروحاتك النصية هي تصويرك السينمائي. استخدم التعديل على مستوى الكلمة لتحقيق أقصى تأثير بصري.
اقرأ
كيف تحول فيديو طويل واحد إلى شهر كامل من YouTube Shorts في 2026
سير عمل قابل للتكرار لتحويل البودكاست والندوات والبث والدروس إلى Shorts عبر الاختيار والبنية والتسميات التوضيحية والمراجعة.
اقرأ
مراجعة Submagic 2026: رأي صادق + 4 أفضل البدائل
مراجعة Submagic 2026: رأي صادق حول السعر، الميزات، ومقارنة مع CapzAi وOpus Clip وCaptions.ai. أي أداة ترجمات فيروسية تختار لمحتواك القصير؟
اقرأ